 |
| I made this in PowerPoint for Mac. Forgive me. |
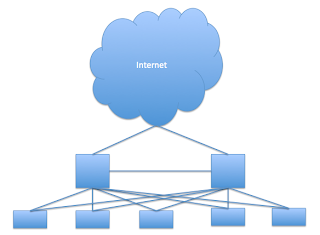
If you've spent any decent amount of time in IT, you've no doubt seen more than your share of "network diagrams" that always have one component in common: a big empty cloud with the word Internet at the top. Something like the diagram on the right.
For server engineers, the cloud at the top of these diagrams was a place holder. It symbolized the domain of the network engineer, where crazy things like BGP and MPLS do... stuff. Packets come in, packets go out: you can't explain that!
Then, 5 years ago, that cloud at the top started to have a new meaning. The cloud was no longer a placeholder, no longer just boilerplate for enterprise architects to pad their Visio drawings. Now it was an active and critical part of the enterprise.
At first, many veteran IT professionals were quick to cast doubt on "cloud computing." It was just another name for hosting, or application server provider, or managed service provider. "In the cloud" was just another buzzphrase that meant "your server is in someone else's data center." It was still your server, still a physical server (ok, 5 years ago, it
may have been a VM, but at least in the government IT space, it was probably still a physical machine), still running a traditional workload. It just happened to be somewhere else.
Cloud computing is just another name for hosting, right?
Well, no. It's easy to understand why so many people think of cloud computing this way. It's all those network diagrams, and a healthy suspicion of new technology that promises to change everything. But to condense the many concepts of cloud computing into "hosting" is to truly miss the point.
Cloud computing is less about where your server is, and more about how your IT infrastructure supports your business. Sure, hosting may be part of cloud computing. But the core tenets of cloud (elastic computing, automation, orchestration, security, and availability) are individually and collectively more significant than the raised floor that supports your hardware.
Remember the IBM marketing term "On Demand?" (full disclosure: I worked at Big Blue a long time ago. (fuller disclosure: I was an eight bar specialist in SecondLife)) Combine "On Demand" with hosting, and you're starting to get to the meaning of cloud computing. It's about the instant, automated provisioning of VMs to respond to changes in workloads. It's about the seamless migration of workloads to meet resource requirements. It's about the application of policy in a consistent, organized manner. And most importantly, it's about the efficient use of IT resources to satisfy your business requirements.
In contrast, I'll give you one example of what cloud computing is not. Cloud computing is not a single software package that you download and install to create your cloud. Regardless of your hypervisor of choice, cloud computing is more than clicking Next Next Finish. It's aligning the operation of your infrastructure with your business. And it's about letting your IT people solve good problems, instead of running around maintaining physical servers. (Have you heard of #DevOps? Search twitter for it. That's where we'll see big changes in how infrastructures are built and managed in the next 3 years.)
So there you have it. A crash course in cloud computing. Feedback and questions are welcomed and encouraged!
 I ran into a problem a few weeks ago while trying to update VMTools in my Windows 8.1 guest. It's an error I've seen many times over the years with various Windows applications, and when it popped up, I had flashbacks from regedt32 and blowing away keys on Windows 2000.
I ran into a problem a few weeks ago while trying to update VMTools in my Windows 8.1 guest. It's an error I've seen many times over the years with various Windows applications, and when it popped up, I had flashbacks from regedt32 and blowing away keys on Windows 2000.